About
Java CUP JFlex compiler SSA
Toy programming language to ARM assembly compiler, written in Java, that I did for a Compiler Design course at my university. Features a SSA backend with separate spilling and coloring passes. Global next-use analysis is used in the spilling pass, allowing some variables to be preserved in registers across loops without unnecessary spills/reloads. This project scored a full 100/100 for all 3 components (Parsing, Type Checking/IR Generation, Backend).
CS4212-Compiler Playground
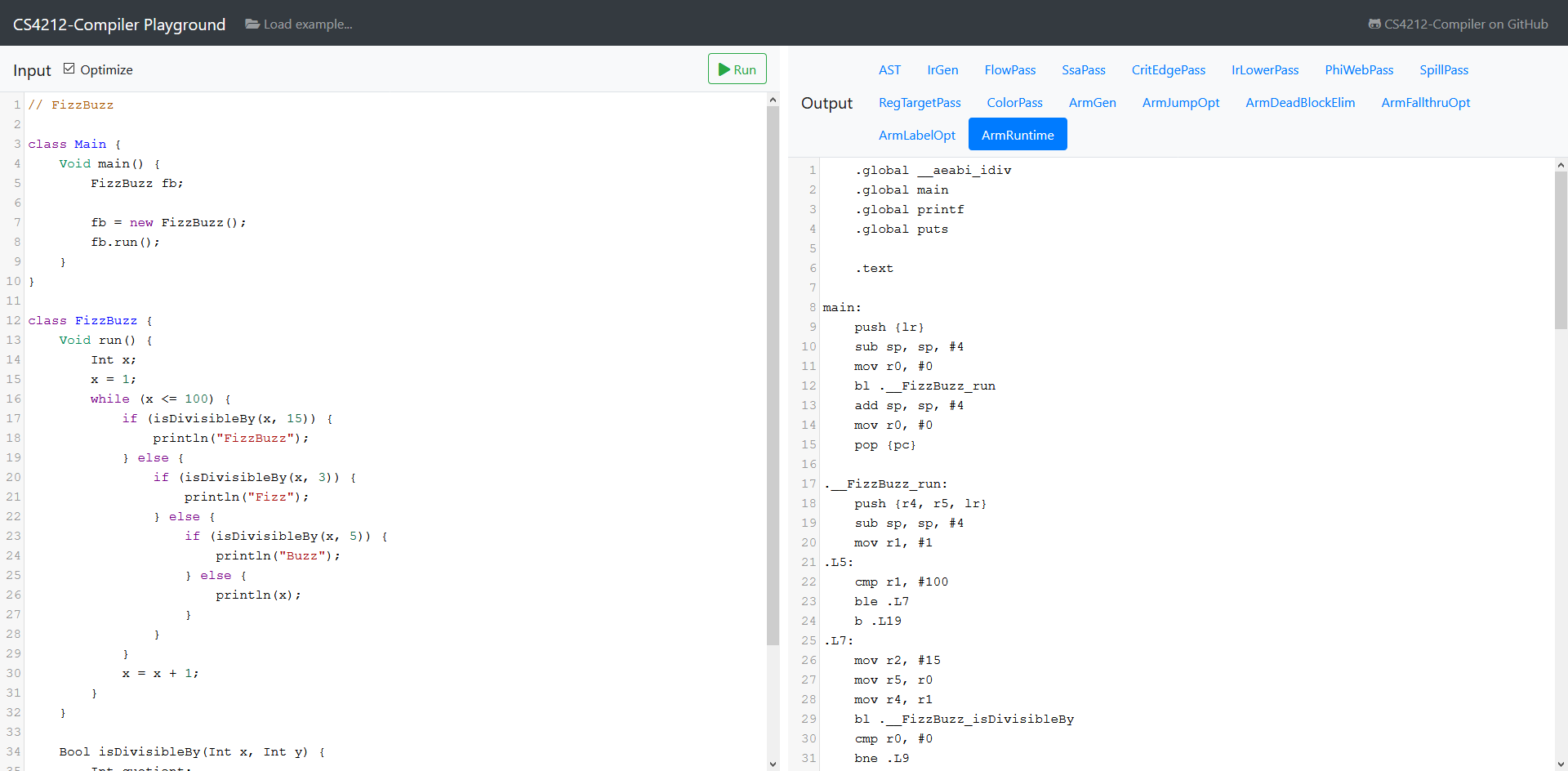
Try out CS4212-Compiler @ CS4212-Compiler Playground without needing to install it on your computer!
Try out CS4212-Compiler @ CS4212-Compiler Playground
Gallery
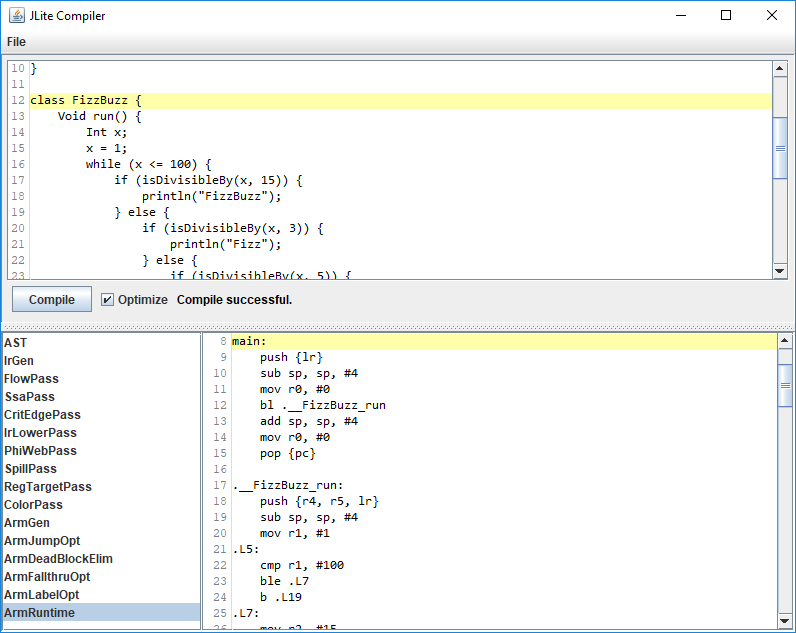
Usage
You must have JDK 8 and above installed.
Clone the repo:
git clone https://github.com/pyokagan/CS4212-CompilerCompile and run the compiler:
cd CS4212-Compiler
./gradlew runA GUI will pop up, allowing you to edit a JLite program and compile it.
You can view the AST/IR/Assembly at various stages of compilation by selecting the associated pass (AST, IrGen, FlowPass etc.)
See File > New from Example for some example programs.
The final pass is ArmRuntime.
If you are using an ARM system or have an ARM GCC cross-compiler installed, you can compile the ARM assembly output from that pass with:
arm-linux-gnueabi-gcc -march=armv7-a assembly.s --staticwhere assembly.s is the file containing the ARM assembly.
Note
-march=armv7-a is needed as the generated assembly relies on a MUL that accepts the same destination register as source register.
Example Programs
Hello World
class Main {
Void main() {
println("Hello World!");
}
}Hello World (Output Assembly)
.global main
.global puts
.text
main:
push {lr}
sub sp, sp, #4
ldr r0, =.L3
bl puts
add sp, sp, #4
mov r0, #0
pop {pc}
.data
.L3:
.asciz "Hello World!"FizzBuzz
class Main {
Void main() {
FizzBuzz fb;
fb = new FizzBuzz();
fb.run();
}
}
class FizzBuzz {
Void run() {
Int x;
x = 1;
while (x <= 100) {
if (isDivisibleBy(x, 15)) {
println("FizzBuzz");
} else {
if (isDivisibleBy(x, 3)) {
println("Fizz");
} else {
if (isDivisibleBy(x, 5)) {
println("Buzz");
} else {
println(x);
}
}
}
x = x + 1;
}
}
Bool isDivisibleBy(Int x, Int y) {
Int quotient;
quotient = x / y;
return quotient * y == x;
}
}FizzBuzz (Output Assembly)
.global __aeabi_idiv
.global main
.global printf
.global puts
.text
main:
push {lr}
sub sp, sp, #4
mov r0, #0
bl .__FizzBuzz_run
add sp, sp, #4
mov r0, #0
pop {pc}
.__FizzBuzz_run:
push {r4, r5, lr}
sub sp, sp, #4
mov r1, #1
.L5:
cmp r1, #100
ble .L7
b .L19
.L7:
mov r2, #15
mov r5, r1
mov r4, r0
bl .__FizzBuzz_isDivisibleBy
cmp r0, #0
bne .L9
mov r0, #3
mov r1, r5
mov r2, r0
mov r0, r4
bl .__FizzBuzz_isDivisibleBy
cmp r0, #0
bne .L12
mov r0, #5
mov r1, r5
mov r2, r0
mov r0, r4
bl .__FizzBuzz_isDivisibleBy
cmp r0, #0
bne .L15
mov r0, r5
bl println_int
mov r1, r4
mov r0, r5
b .L17
.L15:
ldr r0, =.L20
bl puts
mov r1, r4
mov r0, r5
b .L17
.L12:
ldr r0, =.L21
bl puts
mov r1, r4
mov r0, r5
b .L17
.L9:
ldr r0, =.L22
bl puts
mov r1, r4
mov r0, r5
.L17:
add r0, r0, #1
mov r2, r1
mov r1, r0
mov r0, r2
b .L5
.L19:
add sp, sp, #4
pop {r4, r5, pc}
.__FizzBuzz_isDivisibleBy:
push {r4, r5, lr}
sub sp, sp, #4
mov r5, r1
mov r1, r2
mov r4, r1
mov r0, r5
bl __aeabi_idiv
mul r0, r0, r4
cmp r0, r5
beq .L26
mov r0, #0
b .L29
.L26:
mov r0, #1
.L29:
add sp, sp, #4
pop {r4, r5, pc}
println_int:
push {r4, lr}
mov r1, r0
ldr r0, =.PD0
bl printf
pop {r4, pc}
.data
.L20:
.asciz "Buzz"
.L21:
.asciz "Fizz"
.L22:
.asciz "FizzBuzz"
.PD0:
.asciz "%d\n"Language Overview
JLite is a toy programming language with some basic data types, some basic arithmetic and logical operators, records, functions and function overloading (ad hoc polymorphism).
Entry Point
The first class in the file must be the "Main" class.
This class can be called anything,
but it must only contain a single method with the signature Void main(). It cannot have any fields.
This class will be the main entry point to the program.
Data types, Literals and Classes
The following types are built-in:
| Type name | Description |
|---|---|
Int | 32-bit signed integer |
Bool | Boolean type. Only accepts true or false values. |
String | Pointer to a NUL-terminated string, or null. |
Values of built-in data types can be constructed with the following literal syntax:
| Name | Example | Description |
|---|---|---|
| String Literals | "this is a string" | A quoted sequence of ASCII characters. The escape sequences \\, \n, \r, \r and \b are recognized, as well as decimal and hexadecimal base escapes (e.g. \032, \x08). |
| Boolean literals | true or false | |
| Integer Literals | -2, -1, 0, 1, 2, 3 etc. | |
| Null Literals | null | A subtype of String and all classes. |
In addition, users can define their own record types (called classes in JLite, although they aren't as powerful as real classes).
Class names are a sequence of alphabets, digits and underscore, starting with an uppercase letter.
On the other hand, field names and variable names are a sequence of alphabets, digits and underscore, starting with a lowercase letter.
This source fragment defines a class Foo with fields bar and baz, with the types Int and String respectively:
class Foo {
Int bar;
String baz;
}Instances of classes can be constructed with:
new Foo();Note
This will allocate memory directly with malloc(), and so fields will be uninitialized.
You can assign values to the instance fields with:
Foo foo = new Foo();
foo.bar = 4;
foo.baz = "some string";You can also assign field values to the current instance with:
class Foo {
Int bar;
String baz;
Void f() {
bar = 2;
baz = "some string";
}
}Or, if the field name happens to be shadowed in the current scope, you can use this:
class Foo {
Int bar;
String baz;
Void f() {
this.bar = 2;
this.baz = "some string";
}
}Methods
Classes can have zero or more methods. In addition, methods can be overloaded based on their number of arguments or argument types.
The following example shows method overloading in action:
class Main {
Void main() {
Foo foo;
foo = new Foo();
foo.f(4); // Calls f(Int)
foo.f("hello world"); // Calls f(String)
foo.f(foo); // Calls f(Foo)
foo.f(null); // COMPILE ERROR: ambiguous method call
}
}
class Foo {
Void f(Int x) {
println("f(Int) called");
}
Void f(String x) {
println("f(String) called");
}
Void f(Foo x) {
println("f(Foo) called");
}
}As the example also shows, due to subtyping,
method calls with null literals could be ambiguous.
The type checker will terminate with an error in that case.
The method body consists of zero or more declarations of local variables and one or more statements. Declarations must always come before statements. The following program shows local variables being declared and used:
class Main {
Void main() {
Int x;
Int y;
x = 1;
y = x + x;
println(y);
}
}JLite also comes with a variety of built-in functions:
| Function signature | Description |
|---|---|
readln(Int) | Reads an integer from stdin. |
readln(String) | Reads a line from stdin. No trailing newline. |
readln(Bool) | Reads a boolean value (true or false) from stdin. |
println(String) | Prints the string, followed by a newline, to stdout. |
println(Int) | Prints the integer, followed by a newline, to stdout. |
println(Bool) | If true, prints true, followed by a newline, to stdout. Otherwise, prints false, followed by a newline, to stdout. |
Operators
JLite contains most basic arithmetic and logical operators found in other programming languages.
| Precedence | Operator (and its operand types) | Result type | Description |
|---|---|---|---|
| 5 | -Int | Int | Unary arithmetic negation |
| 5 | !Bool | Bool | Unary logical negation |
| 4 | Int / Int | Int | Arithmetic division with truncation |
| 4 | Int * Int | Int | Arithmetic multiplication |
| 3 | Int + Int | Int | Arithmetic addition |
| 3 | Int - Int | Int | Arithmetic subtraction |
| 2 | Int < Int | Bool | Less than |
| 2 | Int > Int | Bool | Greater than |
| 2 | Int <= Int | Bool | Less than equal |
| 2 | Int >= Int | Bool | Greater than equal |
| 2 | t == t, where t is any type | Bool | Equal |
| 2 | t != t, where t is any type | Bool | Not Equal |
| 1 | Bool && Bool | Bool | Logical and |
| 0 | Bool || Bool | Bool | Logical or |
Control flow statements
If Statements
if (condition) {
... one or more statements ...
} else {
... one or more statements ...
}- The braces are necessary.
- An if statement must have one then block and one else block. Both blocks must have at least one statement.
conditionmust evaluate to aBool.
While statements
while (condition) {
... one or more statements ...
}- The braces are necessary
- The loop body must have at least one statement.
conditionmust evaluate to aBool.
Reserved names
These words cannot be used as class names or identifiers:
classIntBoolStringVoidifelsewhilereadlnprintlnreturntruefalsethisnewnullmain
Compiler Internals
Intermediate Representations
The program transitions through different immediate representations at different stages of compilation:
AST (
Ast.java)- Untyped AST -- The syntax tree of the program directly after parsing.
- Typed AST -- Syntax tree of the program, annotated with types after type checking.
IR3 (
Ir.java)- High level IR -- Three-address code IR generated from typed AST.
- SSA IR -- High level IR converted into SSA form.
- Low level SSA IR -- SSA form IR lowered into a form that accurately models register pressure and target architecture constraints.
- Arm (
Arm.java) -- Models ARM assembly. Whole-program peephole optimizations are done on it.
Parsing (minijava.cup, minijava.flex)
Outputs untyped AST.
Type checking (StaticCheck)
Performs type checking on the AST, and annotates the AST with types. This pass also resolves method overloading.
Implementation of Method Overloading
The main mechanism used is the introduction of a new type, Ast.PolyFuncTyp.
This type represents a non-empty collection of possible Ast.FuncTyps.
Given methods defined like this:
Void f(String x) {
...
}
Void f(SomeClazz x) {
...
}And a method call like this:
this.f("abc");We first query the type of this.f, which is an Ast.PolyFuncTyp with the Ast.FuncTyps:
[String] -> Void[SomeClazz] -> Void
We then examine the argument types of the method call, which is:
[String]We then check to see if the arguments are assignable to any of the possible Ast.FuncTyps.
In this case, only one Ast.FuncTyp matches:
[String] -> Void
and so we call that.
Control flow graph construction (FlowPass)
Uses the basic block construction algorithm (Algorithm 8.5) as described in aho2003compilers to construct a directed control flow graph.
In addition, it guarantees the following:
- An empty "entry" block is inserted at the entry point of the control flow graph. This guarantees that the entry block has no incoming edges. This property is needed for the correct placement of PHI nodes when the body of a method is a loop.
- All basic blocks either end with a
CmpStmtor aGotoStmt. This simplifies the cases we need to consider to modify the control flow graph, as we do not need to consider whether the last instruction of a block is a "goto" or a "fallthrough". - Unnecessary labels that are not the target of jumps are removed.
- Dead blocks that are not reachable from the entry block are removed. This could be considered an optimization, however it is always required because later algorithms expect a single immediate dominator tree. If there are blocks not reachable from the start node, and they are not pruned, they will form multiple immediate dominator trees.
Dominator tree construction (DomPass)
Computes the immediate dominator tree for the control flow graph. This information is needed for the next step (dominance frontier computation).
- A block dominates a block if every path from the entry block to must go through . By definition, every block dominates itself.
- The immediate dominator of a block is the unique block that strictly dominates but does not strictly dominate any other block that strictly dominates .
- The immediate dominator tree represents the dominance relationship between blocks. The parent of each block in the tree is its (unique) immediate dominator.
Every block, with the exception of the entry block, will have an immediate dominantor. The entry block dominates all other blocks in the CFG.
The algorithm used is described in cooper2001simple. It uses a data-flow approach that is similar to Algorithm 9.38 described in aho2003compilers. However, rather than using sets or bitvectors directly, it represents dominance information compactly in an immediate dominator tree.
Dominance frontier computation (DomFrontierPass)
Computes the dominance frontier for each block. The dominance frontier of a block is the set of blocks where 's dominance ends -- that is, a block is in the dominance frontier of if dominates a predecessor of but does not strictly dominate .
In the context of SSA construction, for a definition in block , 's dominance frontier indicates the blocks where a PHI function for needs to be placed.
This pass uses a simple algorithm described in cooper2001simple.
Semi-pruned SSA construction (SsaPass)
This pass converts all instructions in the method to semi-pruned SSA form. Semi-pruned SSA form is:
- strict -- Any definition will dominate its use.
- semi-pruned -- It tries not to create PHI functions whose definitions are not used. (PHI functions are only inserted for variables that live past its block.)
In addition, the SSA form is conventional.
Definitions which are connected by PHI-nodes (phi webs) will never be live at the same time at any program point.
This property will be exploited later on in PhiWebPass when assigning stack locations to variables.
The algorithm used in this pass is based upon the minimal SSA construction algorithm described by rastello2016ssa. It consists of two parts:
- PHI-function insertion (Algorithm 3.1), where for each definition of a variable ,
phi functions are inserted at its dominance frontier.
This uses the dominance frontiers computed in
DomFrontierPass. - Variable renaming (Algorithm 3.3), where multiple definitions of a single variable are renamed into different names, and uses of the definitions are renamed accordingly.
However, the algorithm would insert PHI functions whose definitions are never used. As such, the algorithm was modified to produce semi-pruned SSA form, where phi-function insertion will only be done for a variable if lives past its block. This helps remove lots of unnecessary PHI functions for temporary variables which are defined and only used within the same block.
Semi-pruned SSA algorithm was chosen (as compared to pruned SSA form) as it did not require a full liveliness analysis while still producing pruned SSA form in most cases.
Critical edge splitting (CritEdgePass)
A critical edge is an edge from a block with several successors to an edge with several predecessors.
In the JLite language, this could occur when an if statement branches into a while loop.
Critical edges are troublesome because they prevent us from inserting coupling code (code that needs to run when we move along an edge from one block to another).
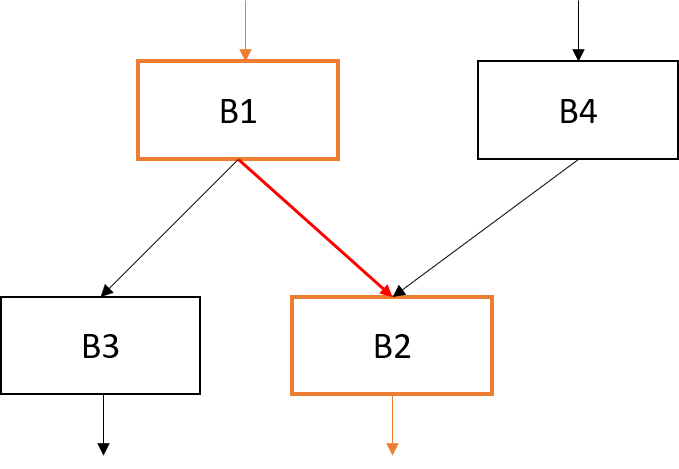
For example, for a critical edge from block B1 to B2, we can't insert the coupling code at the end of B1 because it would wrongly be run when going from B1 to B3, but we also can't insert the coupling code at the start of B2 because it would wrongly be run when going from B4 to B2.
We thus need to split the critical edge into a new block B5 like this:
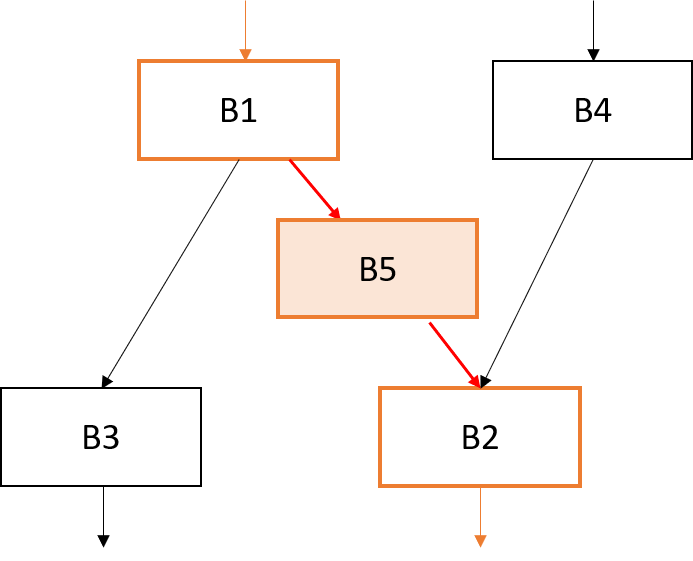
The insertion of coupling code is needed in the spilling pass (for inserting spills/reloads) and the code generation pass (for inserting register transfer code to ensure all registers are in the correct place when going from one block to another).
This pass identifies such critical edges and breaks them by inserting an empty block in between. Since this pass modifies the CFG, the immediate dominator tree and dominance frontier sets will need to be re-computed.
Architecture-dependent IR Lowering (IrLowerPass)
The ARM instruction set allows certain constants to be encoded directly into certain instructions, without needing a separate memory load.
To support the possibility of generating such optimal code,
IR3 allows most operands to be constants.
For example, 1 + 2 can be represented directly as:
%t1 = 1 + 2;Rather requiring 1 and 2 to be in separate variables as follows:
%t2 = 1;
%t2 = 1;
%t3 = 2;
%t1 = %t2 + %t3;However, not all constants can be encoded directly into the instruction. Furthermore, in ARM, only the second operand can be a constant, the first operand must be a register.
During the spilling pass, register pressure must be accurately represented by the IR using variables, otherwise we will run into trouble in the coloring or code generation stages where there are not enough registers available.
As such, the IrLowerPass does such architecture-dependent lowering of the IR.
An Add instruction such as:
%t1 = %t2 + 482645;will be lowered into:
%t3 = 482645;
%t1 = %t2 + %t3;because 482645 is not a valid Operand2 and thus can't be encoded directly into the ADD instruction.
IrLowerPass performs the following:
new Foo()is converted intomalloc(sizeof_Foo), wheresizeof_Foois the size of theFoostruct.readln(x)is converted intox = readln_string(),x = readln_int()orx = readln_bool(), depending on whether the type ofxis aString,Int, orBool.println(x)is converted intoputs(x),println_int(x)orprintln_bool(x)depending on whether the type ofxis aString,IntorBool.a / bis converted into__aeabi_idiv(x)because ARM does not have any division instruction.- Operand2 modeling: For instructions that support an Operand2,
IrLowerPasswill try to put a constant inside the second operand as much as possible, including re-arranging the operands if possible. However, if a valid configuration cannot be found,IrLowerPasswill move them out into temporary variables. - Calling convention modeling: All call stmts are shortened to only 4 arguments, to model the first 4 arguments being passed in R0-R3. The rest of the arguments are kicked out into separate
StackArgStmtinstructions, modeling them being assigned to their associated locations on stack.
Phi Web assignment (PhiWebPass)
This pass performs discovery of phi webs using a union-find pattern with a union-find disjoint set.
A phi web contains variables related by phi functions. That is, given a phi function such as:
a = PHI(b, c, d)a, b, c, d are all elements of the same phi web.
We assume that the program is in Conventional SSA form, that is, each variable in a phi web do not have overlapping live ranges. This means that it is safe to assign each variable the same home location in memory.
Spilling (SpillPass)
hack2005interference showed that the interference graphs of SSA form programs are chordal. For chordal graphs (which are perfect), the chromatic number of the graph is equal to the size of the largest clique.
This means that if the spilling phase ensures that the number of variables live at any point in the program does not exceed the number of registers, a valid coloring can be found by doing a pre-order walk of the dominance tree.
Building on this result, this also means that spilling only needs to happen once, and spilling and coloring can happen in separate phases.
The spilling algorithm used is the one described by braun2009register, although the final implementation is different in some ways. The approach is a modified version of Belady's MIN algorithm -- when register pressure exceeds the number of available registers, the variable whose next use distance is the greatest will be spilled.
One aspect which the above paper glosses over is what to do when PHI nodes are spilled. The approach taken is as follows: The PHI node is transformed into a PHI-MEM node. For PHI-MEM nodes, its arguments must already be spilled when entering the block. Since the program is assumed to be in Conventional SSA Form, the arguments will all occupy the same stack location, and thus no memory-to-memory moves will need to be performed. The definition of the PHI-MEM node itself is not loaded into a register, and will need to be reloaded later on in the block.
SSA Reconstruction (SsaReconstructPass)
When additional reloads are inserted in the spilling pass, multiple definitions of the same variable are introduced into the program, breaking SSA form. To restore SSA form, an SSA reconstruction algorithm is run after the spilling pass. It uses the SSA reconstruction algorithm (Algorithm 5.1) described by rastello2016ssa.
Register targeting (RegTargetPass)
In the ARM calling convention, the first four arguments must be placed in registers R0-R4, and the result will be assigned to register R0.
However, if a chordal graph contains two or more nodes pre-colored to the same color, coloring is NP-complete marx2006parameterized.
To work around this, the approach proposed by hack2009register is used. All live ranges that pass through a call are split, effectively breaking the interference graph into two separate graphs. This is done by introducing a parallel copy (CallPrepStmt) just before a CallStmt.
A call:
x = f(a, b, c, d)will be transformed into:
a', b', c', d', l1', l2', l3', ... = a, b, c, d, l1, l2, l3, ...
x = f(a', b', c', d')where l1, l2, l3 etc. are the other live variables.
This ensures that a', b', c', d' will be assigned to registers R0, R1, R2, R3.
Note that there is no free lunch -- the parallel copy forms a register transfer graph which will be resolved by the code generator into many MOV instructions, which leads to less-than-optimal code (although still better than memory ops). To prevent such moves register-coalescing would need to be used, which is NP-complete.
Coloring (ColorPass)
Since the interference graphs of SSA programs are chordal, this means that if its largest clique is less than the number of colors, a pre order walk of the dominance tree would yield a valid coloring sequence.
This property is exploited in the coloring pass to perform register assignment in linear time. The algorithm used is Algorithm 4.2 in hack2006register.
ARM code generation (ArmGen)
Finally, ARM code is generated from the IR3.
While most of it is straightforward (since the IR3 closely models ARM assembly at this point, thanks to IrLowerPass),
the method to take the IR out of SSA form deserves some further explanation:
To take the IR out of SSA form,
PHI statements and register targeting statements (CallPrepStmt) must be removed.
To do that, the code generator will solve a register transfer graph into a series of MOV instructions which will copy the values of registers into their correct place.
For example, in the following IR:
%rtp8 {r0}, a_0_1 {r4}, i_2_1 {r5}, d_3_1 {r6}, b_1_1 {r7} = %lt0 {r4}, a_0_0 {r0}, i_2_0 {r2}, d_3_0 {r3}, b_1_0 {r1};
%t0_4 {r0} = malloc(%rtp8 {r0});The generated register transfer graph is:
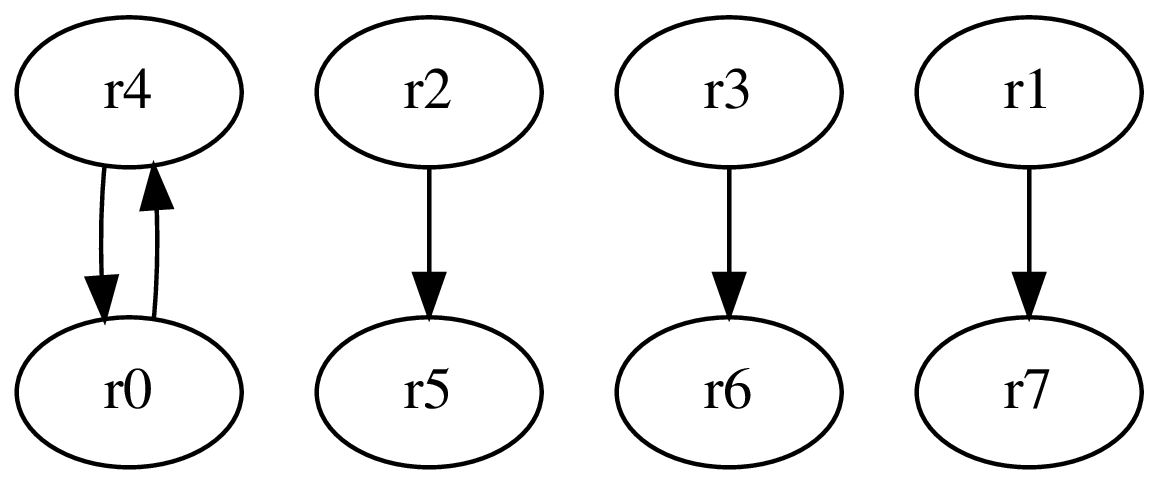
and the generated ARM assembly is:
mov r7, r1
mov r6, r3
mov r5, r2
mov lr, r0
mov r0, r4
mov r4, lrLR is used as a scratch register to break the cycle.
This is possible because LR was already saved in the stack for the method in question.
The algorithm used for sequentializing the register transfer graph is described by hack2006register.
Peephole Optimizations
At this point, we can then (optionally, when optimizations are enabled) perform some peephole optimizations on the generated ARM code.
Eliminating jumps-to-jumps (ArmJumpOpt)
This optimizer will look for labels that simply point to unconditional gotos:
.L1:
b .L2Any branch to .L1 will then be rewritten to directly branch to .L2,
thus saving unnecessary jumps:
b .L1is rewritten to:
b .L2Eliminating dead blocks (ArmDeadBlockElim)
Due to jump-to-jump elimination, and perhaps because the original JLite source program did not use all methods in the source file, some code blocks will be dead.
ArmDeadBlockElim will perform a reachability analysis from the main block in the file,
and remove any blocks that are not reachable by jumps.
Convert jumps to fallthroughs (ArmFallthruOpt)
This is a simple optimizer that removes jumps that simply jump to the next instruction:
...
b .L1
.L1:
...becomes:
...
.L1:
...Remove unused labels (ArmLabelOpt)
Another simple optimization pass that removes labels that are never jumped to.
Runtime injection (ArmRuntime)
At this point, the implementation of some runtime support functions such as println_int(), readln_string() etc are still missing.
This pass will detect if the assembly file requires these functions,
and will inject their implementations into the assembly file.
This way, the assembly file is entirely self-contained.
Finally, the completed assembly source file is ready to be consumed by the user.
Needs work
- The generated code has lots of
MOVinstructions since no attempt is made at coalescing.