UDML: A minimal sexp-like document markup language
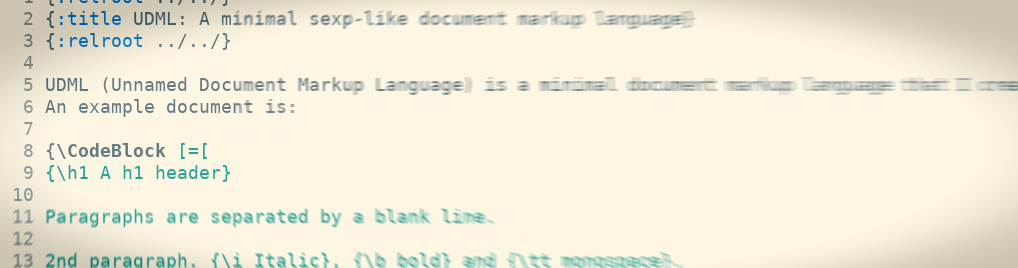
UDML (Unnamed Document Markup Language) is a minimal document markup language that I created for this website. An example document is:
{\h1 A h1 header}
Paragraphs are separated by a blank line.
2nd paragraph. {\i Italic}, {\b bold} and {\tt monospace}.
Here is a link to {\href http://example.com/ a website}.
{\* this is}
{\* an}
{\* itemized list}
{\h2 A h2 header}
{\. This is}
{\. a numbered}
{\. list}In this post I'll describe the background and my thought processes behind the design of this markup language.
Background
The scripts generating this website are written in Lua. As such, finding a suitable markup language to use for this website's content (e.g. blog posts, project pages) was a bit of a problem, given that, from a cursory Google search, the only available Lua libraries were for Markdown, which I didn't really like since from experience Markdown parsers usually have a lot of hidden gotchas (due to a historical lack of a spec) and there isn't a way to "extend" the syntax without dropping down to verbose HTML tags. Anyway, the repositories of those Lua libraries seemed pretty dead, just like many other Lua libraries I've found on web searches. Must be a Lua thing.
So, I decided to write my own parser for a more fully-featured markup language such as restructuredText or asciidoc. I decided to go with reST since it has a spec and I vaguely remembered having a pleasant experience for it the last time I used it for writing documentation. Also, it seemed nice that it consistently used indentation for delimiting indented blocks, and it had interpreted text roles and directive blocks for all my extension needs.
However, after a while,
I found some deficiencies in reST that I missed out at first,
such as how all inline markup could not be nested, including interpreted text roles.
So, one couldn't have Typewritten text that was bold written in a natural manner, for example.
There were also some inconsistencies in practice that were not pointed out in the spec.
For example, the math interpreted text role
seemed to treat backslashes (reST's escape character) specially -- they neither behaved as how they would
as literal text, nor as a normal escape sequence.
These could all be fixed by modifying the language grammar,
of course,
but then I wouldn't be able to call my parser a "reST" parser anymore.
Reading the spec was also time-consuming and
lots of time was also wasted having to cross-check my implementation with docutils.
The entire time I was writing the parser I sorely wished that I didn't need to go through all that trouble in the first place.
As such, I rm -rf'ed the parser and decided to just design an entirely
new minimalistic markup language that
didn't trade-off implementation simplicity for those overly-complex "human-readable syntax" stuff
that is a pain to implement and didn't end up falling apart in practice when you needed to do anything off the beaten track (such as nesting inline markup -_-).
Design goals
I wanted a markup language that:
- is so simple and robust that one only needs an hour or two to write its parser correctly in their favorite programming language. This rule has two benefits: Firstly, it means that I will never need to repeat the horrific "let's write a parser for a complex markup language" experience recounted in the above section ever again. Secondly, if the rules were so simple and robust the language would be much more predictable with less edge-cases, especially with extremely complex document structures such as multiple nested lists and tables.
- Yet, the language should be helpful/convenient enough that one would prefer to use it over writing HTML directly.
To fulfill design goal (2), I considered why we have gravitated towards using markup languages such as Markdown instead of using HTML. From my perspective, the "big sells" of Markdown are the following:
- No
<p>tags. This feature alone greatly frees up the document from markup and greatly enhances readability. - Automatic escaping of HTML special characters (
&,<,>,"and'). Another great feature since one no longer needs to keep the list of special characters and their equivalent HTML entities in their heads. Lighter syntax for certain constructs that are extremely verbose in HTML, such as
Lists:
<!-- VERBOSE! --> <ul> <li>Item1</li> <li>Item2</li> </ul>vs
* Item 1 * Item 2Bold font:
<!-- <strong> is lots of typing just to change the font face --> This text is <strong>bold</strong>.vs
This text is *bold*.
I consider other features like syntax highlighting to be orthogonal since it's not a syntax feature --
one could just write a processor that transforms all <code> HTML tags or something.
Now, of all the features above, I only consider (1) and (2) to be a good approach and a must-have in this new language.
(3) is certainly useful, but I consider the approach of introducing new symbols to denote certain markup
(e.g. using *bold* to mean <strong>bold</strong>) to be a losing battle, since
each handy syntax we add to the language further complicates its grammar (violating design goal (1)).
For example, we now need to think about how to tell apart:
*bold text*from:
* a listNow, we probably might be able to think up of some rule (e.g. the * symbol must be followed by whitespace to be considered a list, or the * symbol must be escaped),
but it's now another rule that the author needs to remember.
Making authors escape symbols defeats one of the reasons why they are using
the language instead of using HTML -- that they don't need to escape the HTML special characters.
imo, rather than going straight to using new symbols for markup,
for the sake of grammar simplicity I think it would be much better to use a single
standard delimiter (such as { and }) and names for describing different kinds of markup,
just like what TeX does. In Plain TeX, one can define a run of text as bold by using:
This text is {\bf bold}.This also means that authors can define new markup just by using different names. There is some extra verbosity, of course, but in my experience it's not really that bad, as long as we assign short names to commonly-used markup. (And really, this is not much different from assigning short strings of symbols to commonly-used markup that other markup languages do.)
Additionally, these markup languages usually recognize that authors may wish to do something that goes beyond what is supported by the language, and give them an escape hatch out of the language, such as the raw directive in reST or using HTML directly in markdown. Yet, dropping down to HTML in Markdown/reST/asciidoc means that the author has to type out the HTML tags in all their verbosity. I think there is room for a markup language to have something in-between -- allow authors to use raw HTML, but give them a better tree language that isn't as verbose.
What kind of better tree language? S-expressions, for example.
Deriving UDML from S-expression syntax
S-expressions are a convenient way of representing lists of data, which can be arbitrarily nested. There are many variants of S-expressions. For our purposes, we define a S-expression as:
- A string, or
- A list of S-expressions.
A string can be represented as the following in lisp syntax:
"foo"Whereas a list can be represented as the following in lisp syntax:
("foo" "bar" "baz")The list contains the items "foo", "bar" and "baz".
Lists can be nested and can be not homogeneous, so the following is a valid list:
("apple" ("banana" "pear") "watermelon")Now, we want to use it to represent the tree structure of a document. We could define the first element of a list to be the HTML element tag. So, the following in HTML:
<h1>Document heading</h1>
<p>Paragraph 1</p>
<p><em>Foo</em>'s bar</p>Can be represented as the following in lisp:
("h1" "Document heading")
("p" "Paragraph 1")
("p" ("em" "Foo") "'s bar")Now, we can see that from the start lisp syntax already massively improves upon HTML syntax by not requiring authors to repeat the tag name in the closing tag, which is why it is the base language of choice that we shall use to derive UDML.
The above approach is nothing new and has been covered extensively in other websites, such as here.
Problem 1: However, we can see a few problems with the syntax that makes it infeasible to write documents using lisp syntax.
The biggest problem currently is that we need to quote strings with ",
which adds unnecessary verbosity and syntactic noise (and also means that ",
which is a common symbol used in prose, needs to be escaped).
To fix this, we shall use Change 1:
Change 1: No string delimiters. The above document would now look like:
(h1 Document heading)
(p Paragraph 1)
(p (em Foo)'s bar)which is much better. The problem is that without the string delimiters, we now can't tell when a single string starts or ends. That's fine for prose though, we can just split by words and parse the above into the following lisp expression:
("h1" "Document" "heading") ("p" "Paragraph" "1") ("p" ("em" "Foo") "'s" "bar")Problem 2: One issue, though. We need to be able to distinguish <em>foo</em>'s and <em>foo</em> 's.
With the former the 's must be stuck to foo as they are a single word, whereas with the latter the 's is a separate word.
As such, we shall make another change which is:
Change 2: Whitespace is significant -- runs of whitespace will be parsed into a single list element. The document will now be parsed into:
("h1" " " "Document" " " "heading") "\n" ("p" " " "Paragraph" " " "1") "\n" ("p" " " ("em" " " "Foo") "'s" " " "bar")The above looks pretty messy, but it is important to note that it is the parse tree -- not what authors see! They will see Listing 5 instead.
Problem 3: One other problem is the use of ( and ) as list delimiters,
which are also common symbols used in prose.
Even if we have an escaping mechanism,
authors would not be happy when they need to escape this character all the time.
Change 3: Use { and } as list delimiters.
{ and } are rarely used in prose and are thus very suitable.
As mentioned previously TeX does this and it works very well.
The document written in UDML would thus become:
{h1 Document heading}
{p Paragraph 1}
{p {em Foo}'s bar}Problem 4: Change 3 creates another problem, though.
We commonly wish to embed code snippits in documents.
However, if { and } are special characters,
we are going to have lots of trouble when embedding code written in e.g. C :-P.
We could require authors to escape them with a backslash,
but the amount of escaping would become annoying when authors embed
snippits with lots of braces.
As such, let's re-use an idea from Lua to fix this:
Change 4: Fenced literal strings. In Lua, a literal string can be defined using the following long format:
where the number of = symbols on both sides are the same.
Likewise, we use the same syntax in UDML.
Inside a fenced literal string, the { and } special characters
will be interpreted literally. For example:
{pre [===[
This is a fenced literal string!
We can use { and } freely inside it without it being interpreted by the parser.
We can even use stuff like [====[ and ]=] too, just as long as the number of ='s don't collide ;-)
]===]}I really like the idea of fenced literal strings since
it guarantees that anything can be encoded within it,
even [====[ and ]=====] as shown above.
If there is a delimiter collision, we can simply construct a new fenced literal string delimiter by adding an extra = :-).
Furthermore, we don't need to add an escape character --- fenced string literals accomplish this for us.
It's nice to have only one way to do things :-).
At this point, we pretty much nearly have the final syntax definition of UDML. The final finishing touch is to add the "paragraph rule":
Change 5: A run of whitespace containing at least two newlines is a paragraph. For example, this:
1st paragraph
2nd paragraphwill be parsed differently from this:
1st paragraph
2nd paragraphIn my parser, I do this by inserting a {\par} node instead of the usual string node
to simplify the code.
This makes it semantically equivalent to:
1st paragraph{\par}2nd paragraphbut such equivalence is not strictly necessary.
This rule complicates the grammar of UDML but, as mentioned previously, I believe this is a "must have" feature that is universally agreed to greatly enhance readability, as evidenced by almost all document markup languages (TeX, markdown, asciidoc, reST etc.) all having this rule :-).
As this point, we are done! UDML can be summarized in the following rules, which I shall call Base UDML.
- A UDML expression is either: (1) A String, or (2) a Paragraph Separator, or (3) a List.
- A String is either: (1) a run of whitespace having one or zero newline characters, or (2) a word not containing whitespace, or (3) a fenced string literal, whose contents are taken literally.
- A Paragraph Separator is a run of whitespace having two or more newline characters.
- A List is a list of UDML expressions delimited by matching
{and}delimiters.
Due to how small the above grammar is, the code needed to implement the parser is also pretty small. Here is an example Javascript parser:
function parse(buf, initialList) {
initialList = initialList || ['\\docroot'];
let stack = [initialList], match;
const re = /(\s+)|\{|\}|\[(=*)\[(.*?)\]\2\]|(\[=*\[)|\[|[^\s\[\{\}]+/y;
while ((match = re.exec(buf)) !== null) {
if (typeof match[1] !== 'undefined') { // whitespace or paragraph
if ((match[1].match(/\n/g) || []).length >= 2)
stack[stack.length-1].push(['\\par']); // paragraph
else
stack[stack.length-1].push(match[1]); // whitespace
} else if (typeof match[3] !== 'undefined') { // literal block
stack[stack.length-1].push(match[3]);
} else if (typeof match[4] !== 'undefined') {
throw new Error('unterminated literal block');
} else if (match[0] === '{') { // block start
const n = [];
stack[stack.length-1].push(n);
stack.push(n);
} else if (match[0] === '}') { // block end
if (stack.length === 1) throw new Error('unmatched }');
stack.pop();
} else {
stack[stack.length-1].push(match[0]);
}
}
if (stack.length !== 1) throw new Error('unterminated {');
return stack.pop();
}You can try it out below:
Note that these rules are completely independent from how HTML is defined. It does not specify how we could, for example, attach attributes to a HTML tag. So, we need to add some more rules, but at this point the syntax starts to veer off into subjective territory. Readers are encouraged to use the above Base UDML as a base to build their own markup which suits their own tastes.
Modeling HTML tags and attributes
With Base UDML, we are able to model documents consisting of arbitrary lists, paragraph separators and strings. However, it doesn't say how we can actually represent an arbitrary HTML document tree in UDML. For one, a HTML document aren't just lists, but rather elements and attributes.
To support this, we add the following rules on top of Base UDML, to form UDML-HTML:
- A Whitespace Node is either a String containing only whitespace characters, or a Paragraph Separator.
- The List Key of a List is either: (1) the first item of a List, or (2) the second item of a List if the first item is a Whitespace Node
- An Attribute is a List whose List Key is a string that starts with
:. Subsequent characters of the string is the attribute name. - An Element is a List whose List Key is a string that starts with
\\. Subsequent characters of the string is the element name. The List Key in the list is followed by zero or more Attributes, which can be separated by Whitespace Nodes, followed by the element's content. - Runs of inline elements (as defined in the HTML spec) separated by Paragraph Separators are
semantically equivalent to wrapping them in
{\p}elements.
Yes, the use of \ was strongly inspired by TeX ;-)
Note that these rules do not require any modifications to the Base UDML parser! We can simply just use the use the output of the parser (strings and lists) directly.
For example, the following HTML document:
<h1>Header 1</h1>
<p>Special characters in HTML: & < ></p>
<p>Some fruits:</p>
<ul>
<li data-quote="I'yummy">Apple</li>
<li>Pear</li>
</ul>can be represented in UDML-HTML as:
{\h1 Header 1}
{\p Special characters in HTML: & < >}
{\p Some fruits:}
{\ul
{\li {:data-quote I'm yummy} Apple}
{\li Pear}}or, by utilizing Paragraph Separators:
{\h1 Header 1}
Special characters in HTML: & < >
Some fruits:
{\ul
{\li {:data-quote I'm yummy} Apple}
{\li Pear}}At this point, we can start to see some of the benefits (no HTML entities, no closing tags,
no <p> tags) ;-).
Improving usability
Yet, using just raw HTML is still a chore, given that the tree structure required by certain HTML tags is still pretty complex. For example, writing lists requires an additional level of nesting:
{\ul
{\li Item 1}
{\li Item 2}}when with Markdown it could just be:
* Item 1
* Item 2To replicate this I implemented a transformation that would transform:
{\* Item 1}
{\* Item 2}into the {\ul} and {\li} elements.
This gracefully handles nested lists as well:
{\* Item 1
{\* Item 1.1}
{\* Item 1.2}}
{\* Item 2
{\* Item 2.1}
{\* Item 2.2}}is transformed into:
{\ul
{\li Item 1
{\ul
{\li Item 1.1}
{\li Item 1.2}}}
{\li Item 2
{\ul
{\li Item 2.1}
{\li Item 2.2}}}}This syntax is not ideal, but in practice imo it is good enough, especially since it doesn't require any additional grammar rules, just an additional (simple) AST transform pass.
Likewise, I have defined admonition block elements:
{\Note A note}which is rendered as:
Note
A note
as well as CodeBlock elements which can perform syntax highlighting:
{\CodeBlock {:syntax python} {:caption A {\b python} script} [=[
print('A python script')
]=]}rendered as:
print('A python script')If you notice, the {:caption} attribute contained markup ("{\b python}")
even though regular HTML attributes can't.
That's a killer advantage of using regular UDML list syntax to represent attributes instead of HTML attribute syntax (as required in Markdown) ;-).
Closing words
Due to the language's minimal grammar, writing the parser took only 4 hours. (And could probably be much less, given that I was designing the grammar while writing the parser) Despite its simplicity, I am actually pleasantly surprised by how well the syntax works in practice, even though it is slightly more verbose compared to other markup languages. For example, the ability to put regular markup inside HTML attributes is a pretty nice property that falls out by just using a simple, powerful core language.
I don't expect everyone to use it, but I do hope that some of the ideas expressed in this post might be useful, and hopefully someone would one day design a widely-used markup language that isn't a pain to write a parser for ;-)